STI Basiswissen – Grundlagen der Sprachverständlichkeit
von Anselm Goertz , Artikel aus dem Archiv vom
Die Sprachverständlichkeit ist die entscheidende Größe zur Bewertung von Lautsprecheranlagen aller Art. Aber wie kann man die Sprachverständlichkeit messen? Hier wird erläutert, wie die Sprachverständlichkeit in Form des Sprachübertragungsindex STI berechnet, gemessen und bewertet wird.
Nahezu alle Gebäude und auch viele öffentliche Freiflächen sind heute mit Lautsprecheranlagen ausgerüstet. Deren Aufgabe ist in erster Linie die Sprachübertragung. Das kann zur Information auf Bahnhöfen und Flughäfen sein, zur Einspielung von Werbung in Einkaufszentren, zur Übertragung eines Sprechers in Konferenz- und Hörsälen oder für Notfalldurchsagen aller Art. Letzteres wird heute kurz als SAA (SprachAlarmAnlage) bezeichnet und muss nach Vorgaben der Norm VDE 0833-4 (Gefahrenmeldeanlagen für Brand, Einbruch und Überfall Teil 4: Festlegung für Anlagen zur Sprachalarmierung im Brandfall) bestimmte Voraussetzungen erfüllen. Wenn es um die Evakuierung von Gebäuden oder anderen Bereichen geht, dann ist die Sprachalarmierung immer die erste Wahl.
Alarmtöne mit Lautsprechern, Hupen oder Sirenen zu übertragen ist zwar meist einfacher und günstiger, erreicht aber bei weitem nicht die Wirkung einer Sprachdurchsage. Jeder kennt den Effekt, wenn ein Alarm ertönt, dass erst einmal niemand reagiert und so unter Umständen wertvolle Zeit verloren geht. Erst wenn der Ernst der Lage wirklich erkannt wird – es dringt z. B. Rauch in die Flure – reagieren die zu evakuierenden Personen und dann natürlich mit der zusätzlichen Gefahr einer Überreaktion in Anbetracht der realen Bedrohung. Mit einer Sprachalarmierung fühlen sich die betroffenen Personen meist direkt angesprochen und können den Anweisungen so deutlich schneller folgen. Außerdem können sie bei Bedarf noch mit wichtigen Zusatzinformationen versorgt werden, wie z. B. Hinweise zum Verlassen des Gefahrenbereichs.
Wichtig ist das vor allem dort, wo man mit einem ständig wechselnden Personenkreis zu tun hat, wie in Bahnhöfen, Flughäfen, Hotels, Sportstätten etc. Die reine Alarmtonalarmierung hat sich dagegen dort bewährt, wo ein gleichbleibender fester Personenkreis betroffen ist, der durch Brandschutzübungen für den Notfall trainiert ist und auch umgehend die richtige Reaktion zeigt, wenn der Alarmfall eintritt. Da ein Sprachalarm nur dann seine gewünschte gute Wirkung zeigt, wenn er auch verstanden wird, muss eine gewisse Mindestverständlichkeit erreicht werden. Gleiches gilt natürlich auch für rein informative Durchsagen wie Reisendeninformationen, Stadionsprecher oder Werbeeinspielungen.
In allen Fällen stellt sich daher die Frage, wie man die Sprachverständlichkeit bewertet – objektiv, reproduzierbar und möglichst unter Berücksichtigung aller Einflussgrößen. Als Messgröße hat sich hier der STI (Speech Transmission Index) etabliert, dessen Messung und Berechnung in der EN 60268-16 (Elektroakustische Geräte-Teil 16: Objektive Bewertung der Sprachverständlichkeit durch den Sprachübertragungsindex) sehr detailliert beschrieben wird. Der STI versucht als Einzahlparameter den gesamten Sachverhalt der Sprachverständlichkeit in einem einfach zu interpretierenden Wert zwischen 0 und 1 darzustellen. In der Praxis sind Werte zwischen 0,35 (quasi unverständlich) bis 0,75 (sehr gut verständlich) üblich. Der kleine Wertebereich und der komplexe Hintergrund mit vielen Einflussgrößen macht die Interpretation des STI daher nicht immer ganz einfach.
Um die Grundlagen des STI zu erklären, müssen wir die Einflussgrößen und Parameter auf die Sprachverständlichkeit betrachten. Aus eigener Erfahrung weiß man, wie sich Störpegel und Nachhall negativ auswirken können. In einer lauten Umgebung wird die Verständlichkeit schnell schlechter bis völlig unbrauchbar. Und wer schon einmal versucht hat, sich in einer Kirche über 10 m Entfernung normal sprechend zu verständigen, kennt auch die ungünstige Auswirkung des Nachhalls. Eine weitere Einflussgröße ist der Sprachpegel als solcher. Wird Sprache zu leise, oder ist die Hörfähigkeit eingeschränkt, fallen abhängig vom Pegel Anteile unter die Hörschwelle und reduzieren somit die Verständlichkeit. Auch dieser Effekt dürfte für jeden leicht nachvollziehbar sein.
Weniger bekannt dagegen ist die andere Seite der Pegelskala: Bei sehr hohen Pegeln lässt die Sprachverständlichkeit ebenfalls nach. Aus Sicht der Psychoakustik steckt der sogenannte Maskierungseffekt dahinter. Laute tieffrequente Anteile in der Sprache verdecken durch die Maskierung leisere höherfrequente Laute und verhindern so deren Wahrnehmung.
Anschaulich dargestellt wirkt sich die Maskierung durch ein besonders lautes Frequenzband als verschlechterter Störabstand für die darüber liegenden Frequenzbänder aus. Relevant wird dieser Effekt für Pegel ab circa 80 dBA. Bezeichnet wird der Effekt auch als Selbstmaskierung, da die Ursache der Maskierung nicht von außen kommt, sondern im Sprachsignal selber begründet ist.
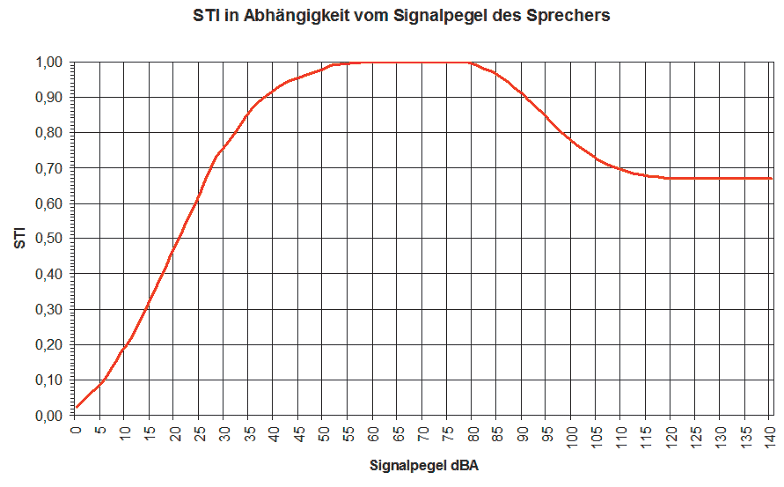
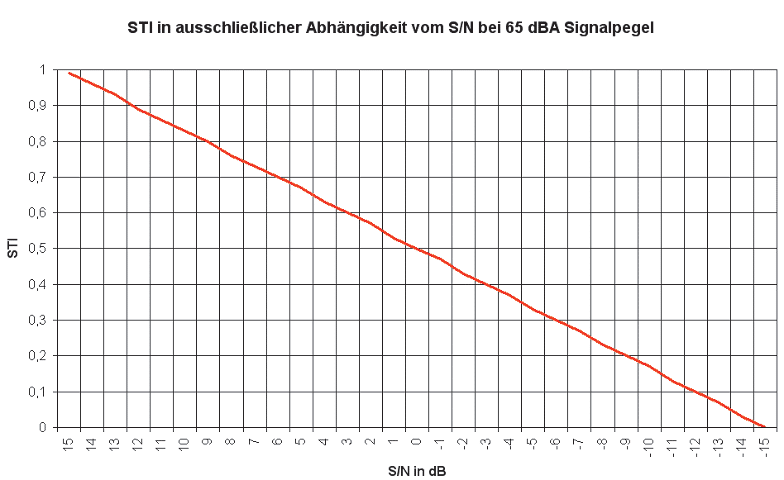
Anselm GoertzABB. 1: STI-Wert in ausschließlicher Abhängigkeit vom Sprachsignalpegel für normal hörende Personen. Unterhalb von 55 dBA wirkt sich die Hörschwelle aus und oberhalb von 80 dBA die Maskierung.Anselm GoertzABB. 2: STI-Wert in ausschließlicher Abhängigkeit vom Verhältnis Signal- zu Störpegel
ABB. 1 zeigt anschaulich die Abhängigkeit der Verständlichkeit vom Sprachsignalpegel, unter ansonsten idealen Voraussetzungen, also ohne anderen Störpegel und ohne Nachhall oder Echos für normal hörende Personen. Kommt ein Hörschaden hinzu, verschiebt sich die untere Flanke hin zu höheren Pegeln und je nach Art des Schadens die obere zu niedrigeren Pegelwerten hin. Ideal für die Verständlichkeit ist somit ein Pegel zwischen 60 und 80 dBA, wo auch die normale bis gehobene Sprechlautstärke liegt. Bleibt man in diesem Bereich, braucht man sich um das Thema Maskierung keine weiteren Gedanken zu machen. Nun kommt es aber häufig vor, dass ein hoher Störpegel vor Ort wesentlich höhere Sprachsignalpegel erzwingt. Denkt man z. B. an Straßentunnel, die aus akustischer Sicht direkt in mehrfacher Hinsicht äußerst kritisch sind, dann herrschen hier Störpegel von bis zu 95 dBA.
Möchte man den Sprachsignalpegel deutlich darüber heben, liegt man schon bei 105 dBA und damit weit in der Maskierung, womit eine ohnehin schon schwierige Situation noch schwieriger wird. Je nach Situation gilt es daher einen optimalen Kompromiss zwischen Signal und Störpegel und Auswirkung der Maskierung zu finden. Wie sich der Störpegel separat betrachtet auswirkt, zeigt ABB. 2. Die Kurve wurde berechnet für 65 dBA Signalpegel und somit ohne Maskierung. Alle anderen Randbedingungen waren wiederum optimal. Bei 0 dB Störabstand wird dann ein STI-Wert von 0,5 erreicht.
Der perfekte Wert von 1 ist erst bei 15 dB Störabstand abzulesen. Die Grafik vereinfacht jedoch einen eigentlich komplexeren Zusammenhang. Streng betrachtet dürfen nicht pauschal die Summenpegel verglichen werden, sondern der Störabstand für jedes Oktavband separat betrachtet werden. Die Grafik geht somit von der Vereinfachung aus, dass der auf der X-Achse aufgetragene Störabstand in allen Oktavbändern gilt.
Betrachtet man ein Sprachsignal aus Sicht der Signaltheorie, gibt es die spektrale Zusammensetzung und die Modulation. Die spektrale Zusammensetzung zeigt, wie stark einzelne Frequenzbänder, also z. B. Oktav- oder Terzbänder, in einem Signal vertreten sind. Die Modulation stellt die Hüllkurve des Signals dar.
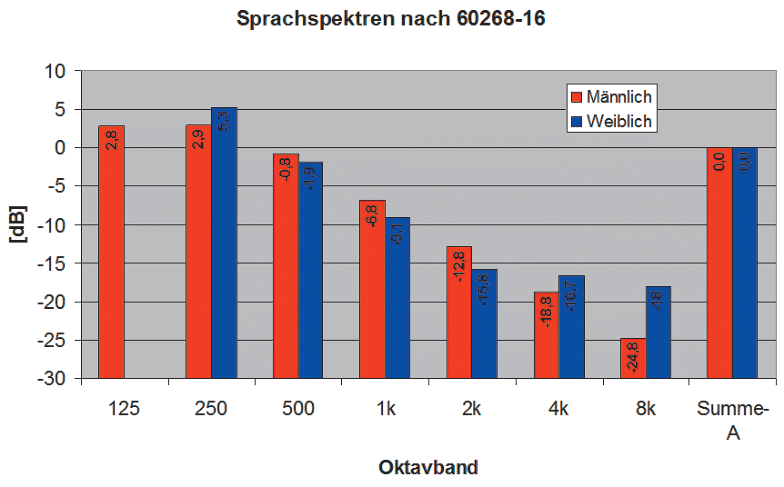
ABB. 3: Unterschiede zwischen Männer- und Frauenstimme – mittlere spektrale Zusammensetzung in Oktavbändern für einen Sprecher (rot) und eine Sprecherin (blau). Beides als Mittelwerte nach EN 60268-16.
Die spektrale Zusammensetzung in ABB. 3 zeigt den primären Unterschied zwischen männlichen und weiblichen Stimmen. Man erkennt, dass bei den Sprecherinnen das 125 Hz-Oktavband fast vollständig fehlt. Daraus resultiert ein handfester Vorteil für die Sprecherinnen:<a Das fehlende 125 Hz trägt kaum zum Informationsgehalt bei, stört aber durch Maskierung und Nachhallanregung in diesem Bereich erheblich. Sprachkonserven arbeiten daher meist auch mit Frauenstimmen, weil diese besser verständlich sind. Genau darin ist auch begründet, dass man bei schlechter Verständlichkeit und dröhnendem Nachhall meist zuerst zum Hochpassfilter greift und damit die 125 Hz Oktave zurücknimmt.
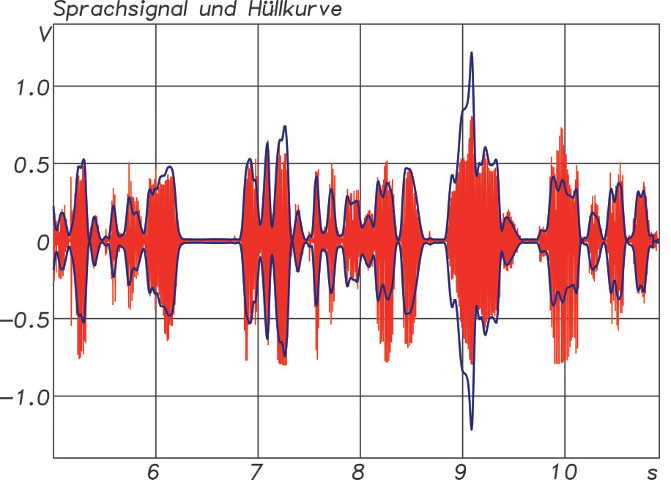
ABB. 4: Sprachsignal (rot) mit Hüllkurve (blau)
Zurück zur Modulation: ABB. 4 zeigt einen Ausschnitt aus einem Sprachsignal und dessen Hüllkurve. Diese wird von Modulationsfrequenzen im Frequenzbereich bis ca. 16 Hz bestimmt. Interessant ist die Modulation vor allem deswegen, weil der Informationsgehalt in der Sprache primär über die Modulation übertragen wird. Wenn man also weiß, wie gut die Modulation bei der Übertragung z. B. über eine Lautsprecheranlage erhalten bleibt, dann lässt sich auch eine konkrete Aussage über die Sprachverständlichkeit treffen.
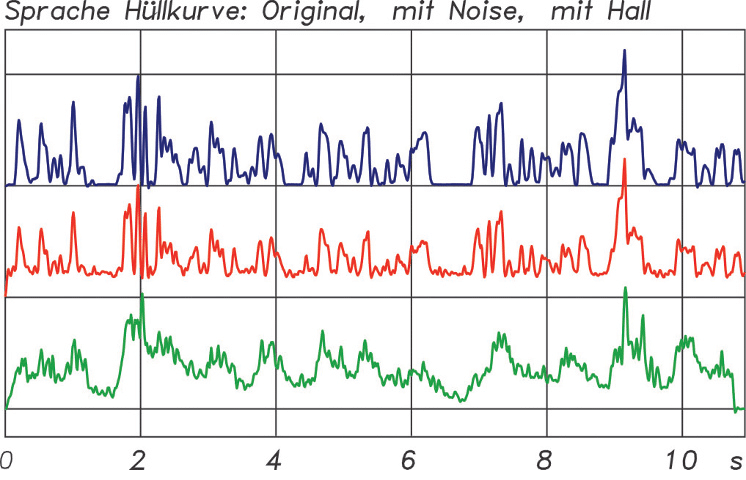
ABB. 5: Die Hüllkurve eines Sprachsignals oben (blau) im Original, in der Mitte (rot) mit Störsignal und unten (grün) mit Nachhall
Wie sich Störpegel oder Nachhall auf die Hüllkurve auswirken, macht ABB. 5 deutlich. Die rote Kurve mit einem Störpegel 6 dB unter dem Signalpegel erreicht noch einen STI-Wert von 0,7. Die grüne Kurve wird durch den Nachhall noch wesentlich stärker gestört und kommt gerade noch auf einen STI-Wert von 0,35.
Für eine mögliche Messung oder Berechnung des STI bedeutet das, den Verlust an Modulationstiefe in einem Signal zu ermitteln. Hier genügt es aber nicht nur einen breitbandigen Wert zu bestimmen. Stattdessen muss nach Frequenzbändern und Modulationsfrequenzen unterschieden werden, um diese ihrer Bedeutung gemäß für die Sprachverständlichkeit zu bewerten. Bei den Frequenzbändern sind die sieben Oktavbänder von 125 Hz bis 8 kHz relevant und bei den Modulationsfrequenzen werden insgesamt 14 Frequenzen von 0,63 Hz bis 12,5 Hz bewertet. Das macht insgesamt 98 Kombinationen. Wie diese genau in die Bewertung einfließen, soll hier nicht näher betrachtet werden, findet sich aber detailliert in der EN 60268-16. Die Grundlage für die Bewertungen entstammen den wissenschaftlichen Arbeiten von Houtgast und Steeneken der 70er und 80er Jahre aus dem niederländischen Labor TNO. Dort wurden in groß angelegten Versuchsreihen die Zusammenhänge zwischen Messwerten und Ergebnissen aus Hörversuchsreihen hergestellt.
Für die Berechnung des STI bedeutet das: Für die 98 Kombinationen aus Oktavbändern und Modulationsfrequenzen ist der Modulationsverlust durch raumakustische Einflüsse wie Nachhall und Echos und durch weitere Faktoren wie Störpegel zu bestimmen. Des Weiteren gilt es denjenigen Signalpegel festzustellen, der den Einfluss durch Maskierung oder Hörschwelle bestimmt.
STI-Messung nach der direkten oder indirekten Methode
Für die Messung des STI sind je nach Methode ein bis drei Schritte erforderlich. Im ersten Schritt wird die Matrix mit den 98 Werten für den Modulationsverlust bestimmt. Die Werte können entweder aus einer gemessenen Impulsantwort über die Rückwärtsintegration nach Schroeder bestimmt werden. Diese Art der Bestimmung nennt sich die indirekte Methode. Oder sie können – als direkte Methode – durch Einzelmessungen mit modulierten Rauschsignalen bestimmt werden.
98 Einzelmessungen wären jedoch sehr zeitaufwändig, so dass man bei TNO die vierzehn wichtigsten Kombinationen aus den 98 bestimmt hat. Es wurde dabei darauf geachtet, dass alle Oktavbänder vertreten sind und eine zeitgleiche Messung aller 14 Kombinationen möglich wird. Dieses etwas vereinfachte Verfahren nennt sich STIPA (STI für PA – Public Address) und kann nach Norm bei Beschallungsanlagen gleichwertig zur vollständigen Auswertung eingesetzt werden. Geräte wie der NTI XL2 Handpegelmesser arbeiten nach diesem Verfahren. Ein entsprechendes STIPA-Testsignal wird von einem Generator, z. B. ein NTI MR-Pro, oder auch von CD abgespielt. Der Handpegelmesser wertet das empfangene Signal aus.
In früheren Zeiten gab es auch noch den RASTI (Room Acoustics STI), der mit nur neun Kombinationen in den Oktavbändern 500 Hz und 2 kHz auskam und primär für einfache raumakustische Evaluationen mit einfachen analogen Messgeräten gedacht war. Der RASTI gehört eindeutig der Vergangenheit an und sollte nicht mehr verwendet werden. Trotzdem taucht der Begriff RASTI auch heute noch regelmäßig in Ausschreibungen etc. auf, was meist in einer schlichten Verwechslung oder Unklarheit zwischen RASTI und STIPA begründet ist.
Sind die 98 oder 14 Modulationsindizes bestimmt, dann ist im Weiteren zu unterscheiden, ob und wie Störpegel und Maskierung zu berücksichtigen sind. Bei der direkten STIPA-Methode ist der Störpegel, falls zum Zeitpunkt der Messung vorhanden, direkt schon in der Messung berücksichtigt. Gleiches gilt für den Nutzsignalpegel, wenn die Anlage mit Nennpegel betrieben wurde. Störpegel und Signalpegel können aber auch beide nachträglich in einer zweiten und dritten Messung erfasst oder auch von extern vorgegeben werden. Diese Möglichkeit ist in der Praxis sehr wichtig, da meist nicht alle Messungen zeitgleich durchgeführt werden können. In einer Shopping Mall wird man so z. B. die eigentliche STIPA-Messung bevorzugt in der Nacht ungestört mit vielen Messpunkten durchführen und diese dann durch eine tagsüber im Normalbetrieb mit Kundschaft durchgeführte Störpegelmessung zu ergänzen.
Wendet man die indirekte Methode an, dann liefern die aus der Impulsantwort berechneten 98 Modulationsindizes nur diese Werte ohne Berücksichtigung von Stör- und Nutzsignalpegel. Beides muss in Oktavbandwerten ergänzt werden. Der Vorteil dieser indirekten Methode liegt in der sehr schnellen und hoch genauen Messung der Modulationsindizes. Für eine normgerechte Messung genügt mit der indirekten Methode eine Messung pro Position.
Direkt gemessen sind je nach Wertebereiche 1–6 Messungen pro Position erforderlich, über die dann zu mitteln ist. Bei einer Messdauer von ca. 20 s pro Messungen ist hier der Zeitfaktor schon erheblich, auch wenn die Geräte die weitere Bewertung und Mittelung meist selbstständig übernehmen. Die indirekte Methode liefert zudem weitere Information in Form der Impulsantworten und Frequenzgänge für alle Positionen, die dann auch für Filtereinstellungen und den Pegelabgleich genutzt werden können. Als Messsignale werden üblicherweise Sweeps oder Rauschsignale eingesetzt.
Sweeps sind hier die erste Wahl, da die Signale besonders robust gegenüber Störungen durch Wind oder Verzerrungen sind. Wichtig ist es darauf zu achten, dass die erfasste Impulsantwort in ihrer Länge für die zu erwartende Nachhallzeit hinreichend ist. Die gemessene Länge sollte mindestens der Nachhallzeit entsprechen. Moderne PC-gestützte Messsysteme haben hier kaum noch Einschränkungen, so dass man immer einen sicheren Wert wählen kann.
Die Mehrzahl der STI-Messungen wird trotzdem mit Handpegelmessern wie dem XL2 von NTI durchgeführt werden, da diese Geräte sehr universell einsetzbar und leicht zu handhaben sind. Speziell der XL2 ist zudem mit reichhaltigem Zubehör, wie z. B. der Talkbox als Sprechersatz für Mikrofonsprechstellen, erweiterbar und kommt als kompaktes gut zu transportierendes Set im Koffer daher. Die komplexeren PC-Messsysteme sind da meist weniger praktisch und verlangen vom Anwender mehr Detailwissen und Einarbeitung.
Konstellationen zur Messung der Sprachverständlichkeit
Fasst man das bisher Gesagte noch mal zusammen, dann gibt es folgende Konstellationen zur Messung der Sprachverständlichkeit:
Über die direkte Methode mit moduliertem Rauschen:
Der übliche Störpegel ist bei der Messung vorhanden und die Anlage lässt sich mit Nennpegel betreiben. Die STI-Messung ergibt dann direkt den finalen Wert.
Der übliche Störpegel liegt während der Messung nicht vor. Die Anlage kann mit Nennpegel betrieben werden. Für diesen Fall ist der Störpegel in der Nachbearbeitung in die STI-Berechnung mit einzubeziehen. Während der eigentlichen STI-Messung sollte der dann noch vorhandene Störpegel so gering sein, dass er keinen Einfluss auf die Messung hat.
Der übliche Störpegel liegt während der Messung nicht vor. Die Anlage kann nicht mit Nennpegel betrieben werden. Für diesen Fall sind sowohl der Störpegel wie auch der Nennpegel mit Sprachsignal in separaten Messungen zu erfassen und in der Nachbearbeitung in die STI-Berechnung mit einzubeziehen. Während der eigentlichen STI-Messung sollte der dann noch vorhandene Störpegel so gering sein, dass er keinen Einfluss auf die Messung hat. Die Messung sollte ohne Maskierung erfolgen, da diese später über den Nennpegel eingeht. Kann man die Maskierung beim verwendeten Messgerät nicht explizit abschalten, ist darauf zu achten, die Messung in einem Pegelbereich unter 80 dBA durchzuführen.
Nach der indirekten Methode über die Messung der Impulsantwort:
Messung der Impulsworten
Messung des Sprachsignalpegels
Messung des Störpegels
Die Auswertung des STI erfolgt aus den Messungen 1 bis 3. Eine zusammenfassende Messung ist hier nicht möglich. Unabhängig von der Messmethode ist bei einer Messung ohne den ortsüblichen Störpegel immer zu beachten: In allen Frequenzbändern muss ein Störabstand von min. 15 dB erreicht werden, um die Messung nicht zu verfälschen.
Bei der direkten Methode sind des Weiteren der Messsignalpegel und die Einstellung des Gerätes zu berücksichtigen. Der Handpegelmesser NTI XL2 bietet hier die Möglichkeiten den STI ohne Maskierung oder mit Maskierung entsprechend der alten gestuften Hörverdeckungskurve oder nach der aktuellen kontinuierlichen Hörverdeckungskurve entsprechend Abbildung 1 durchzuführen. Messungen nach eigentlich veralteten Normen sind manchmal notwendig, wenn sich eine Messvorschrift auf eine speziell datierte Norm bezieht.
Für die Durchführung einer Messung bedeutet das: Sobald die Anlage nicht mit Nennpegel betrieben werden kann, ist ohne Maskierung zu messen und diese später entsprechend des Nennpegels einzurechnen.
Bis hierhin wurden die Grundlagen für die Messung der Sprachverständlichkeit und die möglichen Messmethoden dazu besprochen. In der Praxis kommt den wichtigen Aspekten der Nutz- und Störpegelermittlung sowie der eigentlichen Durchführung und Auswertung der Messungen eine wichtige Rolle zu.







Kommentar zu diesem Artikel
Pingbacks